



Artificial Intelligence in Finance: A Change in Direction
Why and how AI strategy is changing across finance

Artificial Intelligence (AI) in Finance: A Change in Direction
Why and how AI strategy is changing across finance
September 2022
By Fengzi Li
Currently, artificial intelligence (AI) is being used across the financial sector, but how it is being used and the strategies that data scientists and computational linguists in financial institutions employ are starting to change. In the last several years, significant focus has been put on developing large-scale models —complex architectures with billions of parameters — but these advancements may be misleading and the effects may have negative impacts on financial processes.

Why? AI is generally comprised of two main components: Data and Code. In the last decade, AI has mainly focused on enhancing algorithms. However, Andrew Ng,1 one of the most influential AI pioneers, advocates and leads a new revolution in AI society currently about data-centric AI.2 Ng also forecasts the biggest shift in AI will probably be moving the focus from the code (models and parameters) to enhancing the data used in models.
Why It Matters: Accuracy of AI Outcomes + Three Use Cases in Finance
AI models are only as good as the data you feed them. In machine learning (ML), models are built with a high dependency on the data on which they are trained. The maturity and complexity of ML deep learning models and algorithms allow machines to take on more challenging tasks such as language translation, speech-to-text and object detection that power chat bots, RPA, and other advanced automations. These capabilities leverage supervised learning,3 a process in which the quality of the labelled data used is critical.4 Moreover, the nature of AI and ML systems is that machines learn patterns from its training data. For example, an NLP model that was trained to analyze medical documents will not work in other domains, such as finance.
Due to this nature, AI and ML systems will easily break down or deliver sub-optimal results if they encounter any of these common scenarios: training data has a knowledge domain gap as to the problem to be solved; there is bias in the data, or the data is less representative for certain groups; or inadequate or poor quality of data, inappropriate data permutation, poor proxy data or even errors in the ground truth.5

These scenarios can play out in financial institution’s AI in the following ways:
- Bias and Lack of Data in Credit Lending AI: In a study from Stanford and University of Chicago6, researchers collected credit reports for 50 million anonymized U.S. consumers, and tied each of those consumers to their socioeconomic details taken from a marketing dataset, their property deeds and mortgage transactions, and data about the mortgage lenders who provided them with loans. They then experimented with different predictive algorithms to show that credit scores were not simply biased but “noisy,” a statistical term for data that can’t be used to make accurate predictions. They concluded that differences in mortgage approval between minority and majority groups is not just down to bias, but to the fact that minority and low-income groups have less data in their credit histories. Consequently, when this data is used to calculate a credit score that is used to make a prediction on loan default, the prediction will be less precise. It is this lack of precision that leads to inequality.6 A more data-centric AI approach can focus on creating greater equality in this process.
- Poor Data Quality in Fraud Prevention AI: To protect clients’ assets and information, financial institutions must identify bad actors to prevent fraud or malicious behaviors. Due to the vast amount of data, AI is continually employed to make the process more efficient. However, as new types of fraud, asset classes and sectors arise, these systems need to be re-trained. Poor data or outdated data will result in fraud being missed and large penalties for institutions that miss them.7 Hence, a data-centric AI approach can help alleviate this issue.
- Domain Knowledge Gaps in Asset Allocation AI: Through asset allocation AI, a client’s portfolio can be constructed automatically based on their stated risk and return characteristics, among other factors, and trades and rebalancing a portfolio can happen automatically. If there are knowledge gaps in either understanding the client’s needs, resulting in selecting wrong set of training data, or on how to evaluate investments across different sectors or asset classes, and their nuances, AI models, no matter how powerful will not deliver optimal outcomes.8 Leveraging a data-centric AI approach can help create better client services.
How to Address the Challenge
Let’s look at a typical lifecycle of developing and deploying an AI/ML product. Most AI processes can be broken down into five general continuous steps: data collection and labelling, experimentation and development, testing, deployment, and monitoring feedback.
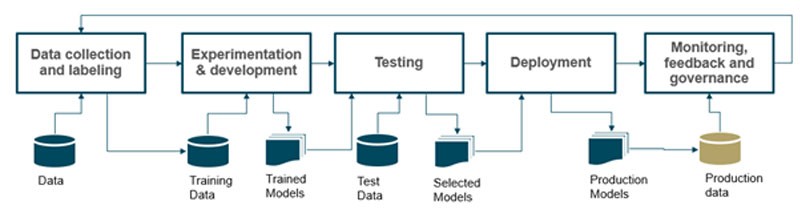
In general, around 70 to 80 percent of development efforts is related to the model’s underlying data,9 starting from data collection, labelling, data preparation/augmentation, and further down the pipeline to monitoring data drift and getting feedback from production environment. Due to the nature of AI and ML systems, models are often trained on a limited set of data during initial training. AI teams probably need to repeat the above different steps for various iterations before the model can be deployed into production and then need to continue to monitor, get feedback, and fulfill the governance requirements after deployment, a process called a continuous training (CT).10
Considering the time spent on tasks related to data in the AI product development lifecycle, ensuring data quality is the key to control technical debts which will drive the success of an AI/ML platforms. This is often neglected as the focus is mostly on the code and algorithm. It is challenging to fully define the “correct” behavior for an ML system upfront11 until it is tested with end users and data in production. Also, there are a lot of unknowns even after deploying an AI model in production, which are addressed with an agile development process.12
Action Steps: Building the Data-centric AI Capability Now
Building the data-centric AI capability will be the key for companies in the financial sector to thrive in the next wave of AI revolution. There are two main aspects that your AI and data science teams and companies must focus on: Data Diagnosis and Data Labelling.
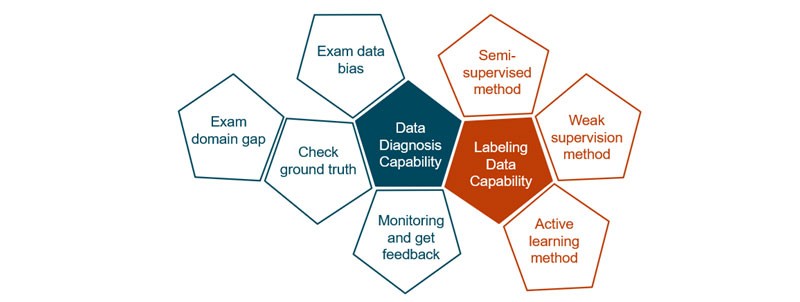
Data Diagnosis – the capability to explore, understand and validate data – tactics are:
- Examine domain gaps to ensure the correct training data is used and is consistent with the production data.
- Identify various types of bias which can enter the AI system development lifecycle without proper controls. This includes biases in data, such as representation bias, proxy bias, measurement bias, data drift bias, etc. Veritas Toolkit13 is an open-source toolkit to help financial institutions to develop responsible AI using Veritas FEAT framework.14
- Validate systematic checking of ground truth – ensuring that labeled data used for training are not erroneous. A technique called Confident Learning15 can be used to help detect labelling errors in your ground truth data.
- Monitoring and feedback loop are essential to make AI products relevant to end users. Continuous monitoring of production data, model performance and user feedback help to detect any anomalies such as data drift in order to control prediction bias in the AI systems and help ensure regulatory compliance.
Labelling Data – the capability to accelerate and systematically obtain quality labeled data — tactics are:
- Leverage machine learning techniques (semi-supervised learning16), which only require training using a small set of labelled data in order to label more data.
- Use of Active Learning17 – carefully selecting a subset of data to be labelled will enable the model to learn more effectively.
- Implement weak supervision18 - is a heuristics method to leverage subject matter expert (SME) knowledge to define labeling functions to train a labeling model for programmatic labeling.
- Leverage tools or products to generate or synthesize more data – there are tools that enable you to generate synthetic data or label more data.19
Conclusion
In conclusion, although the race of building large-scale models isn’t slowing down, a new rising trend of data-centric AI is receiving wider recognition and resonance from the AI community. While powerful models are exciting, if there isn’t enough of the right data to run these models, the advancements are stunted. Furthermore, data-centric AI supports compliance with regulatory considerations to control AI application in finance.
Data science teams at financial institutions must allocate resources to better acclimate to data-centric models with a focus on solid data diagnosis and labelling techniques to ensure that the power of AI models is realized.

- https://hai.stanford.edu/people/andrew-ng
- https://datacentricai.org/
- Stuart J. Russell, Peter Norvig (2010) Artificial Intelligence: A Modern Approach, Third Edition, Prentice Hall ISBN 9780136042594.
- https://www.phdata.io/blog/techniques-for-labeling-data-in-machine-learning/
- https://datacentricai.org/blog/finding-millions-of-label-errors-with-cleanlab/
- https://www.technologyreview.com/2021/06/17/1026519/racial-bias-noisy-data-credit-scores-mortgage-loans-fairness-machine-learning/
- https://www.mckinsey.com/industries/financial-services/our-insights/combating-payments-fraud-and-enhancing-customer-experience
- https://www.forbes.com/sites/ericbrotman/2021/10/28/are-you-putting-too-much-faith-in-your-robo-advisor/?sh=3024196f7a80
- https://www.datanami.com/2020/07/06/data-prep-still-dominates-data-scientists-time-survey-finds/
- https://ml-ops.org/content/mlops-principles
- https://datacentricai.org/data-in-deployment/
- https://scrumguides.org/
- https://github.com/veritas-toolkit/
- https://www.mas.gov.sg/news/media-releases/2022/mas-led-industry-consortium-publishes-assessment-methodologies-for-responsible-use-of-ai-by-financial-institutions
- Northcutt et al. Confident Learning: Estimating Uncertainty in Dataset Labels. arXiv:1911.00068v5 [stat.ML] 8 Apr 2021.
- Olivier Chapelle, Bernhard Scholkopf, et al. (2010) Semi-Supervised Learning (Adaptive Computation and Machine Learning series) 1st Edition. ISBN-13: 978-0262514125
- https://arxiv.org/abs/2109.04847
- http://ai.stanford.edu/blog/weak-supervision/
- https://datagen.tech/guides/synthetic-data/synthetic-data-generation/
BNY Mellon is the corporate brand of The Bank of New York Mellon Corporation and may be used to reference the corporation as a whole and/or its various subsidiaries generally. This material does not constitute a recommendation by BNY Mellon of any kind. The information herein is not intended to provide tax, legal, investment, accounting, financial or other professional advice on any matter, and should not be used or relied upon as such. The views expressed within this material are those of the contributors and not necessarily those of BNY Mellon. BNY Mellon has not independently verified the information contained in this material and makes no representation as to the accuracy, completeness, timeliness, merchantability or fitness for a specific purpose of the information provided in this material. BNY Mellon assumes no direct or consequential liability for any errors in or reliance upon this material. BNY Mellon will not be responsible for updating any information contained within this material and opinions and information contained herein are subject to change without notice.
BNY Mellon assumes no direct or consequential liability for any errors in or reliance upon this material. This material may not be reproduced or disseminated in any form without the prior written permission of BNY Mellon. Trademarks, logos and other intellectual property marks belong to their respective owners.
© 2022 The Bank of New York Mellon Corporation. All rights reserved.